Most developers learn technologies like Redis, Kafka, Load Balancers, CDNs, Kubernetes, and Microservices separately.
They know what these technologies are.
But very few understand why these technologies exist in the first place.
The truth is that most scalable systems don’t start with Redis.
They don’t start with Kafka.
They don’t start with Kubernetes.
And they definitely don’t start with dozens of microservices.
Real systems evolve gradually.
They evolve because every stage of growth introduces a new bottleneck.
Once that bottleneck becomes painful enough, engineers introduce a new architectural component to solve it.
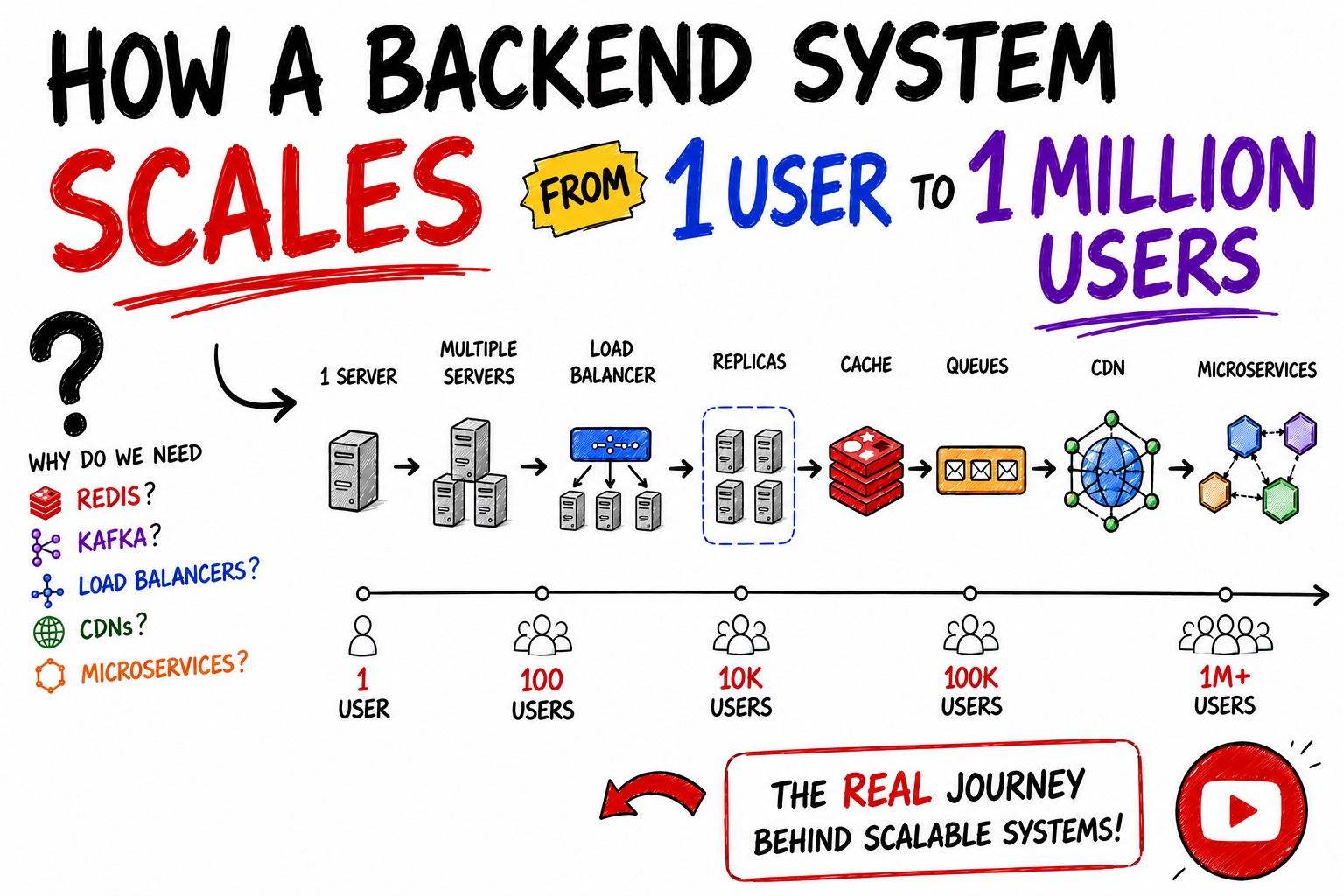
This article walks through the complete journey of how a backend system evolves from serving a handful of users to serving millions.
How System Scales from 1 User to 1 Million Users Video Tutorial
Stage 1: The Beginning — One Server, One Database
Imagine you’ve just launched a startup.
Maybe it’s an e-commerce platform.
Maybe it’s a social media application.
At this stage, very few people are using your product.
Perhaps 10 users.
Perhaps 100 users.
Your architecture looks incredibly simple:
- One backend server
- One database
That’s it.
The backend handles:
- Authentication
- Business logic
- API processing
- Data validation
The database stores all application data.
Surprisingly, this architecture is completely fine.
In fact, this is where many engineers make their first mistake.
They try to build Google-scale systems before they have Google-scale traffic.
They introduce:
- Microservices
- Kubernetes
- Service Meshes
- Distributed Databases
Long before they actually need them.
The result?
Unnecessary complexity.
At the beginning, simplicity is a superpower.
Stage 2: Traffic Starts Growing
Now imagine your application becomes successful.
More users join.
Traffic increases.
Instead of serving hundreds of users, you’re serving thousands.
Suddenly your single server starts struggling.
Symptoms begin to appear:
- CPU utilization spikes
- Memory consumption increases
- Response times become slower
- Users start complaining
The first solution companies typically use is called Vertical Scaling.
Instead of changing the architecture, they simply upgrade the machine.
More CPU.
More RAM.
More powerful hardware.
This approach is attractive because it requires minimal code changes.
No distributed systems.
No networking complexity.
No synchronization problems.
For many applications, vertical scaling can take you surprisingly far.
But eventually, every machine has a limit.
You cannot infinitely increase server size.
At some point, a single machine is no longer enough.
Stage 3: Horizontal Scaling and Load Balancers
Once vertical scaling reaches its limits, companies move to the next step.
Instead of one backend server, they deploy multiple backend servers.
Now traffic can be distributed across machines.
However, a new question emerges:
Which server should handle each request?
This is where load balancers enter the architecture.
A load balancer sits in front of backend servers and distributes incoming requests.
For example:
- Request A → Server 1
- Request B → Server 2
- Request C → Server 3
This prevents individual servers from becoming overloaded.
This approach is called Horizontal Scaling.
Instead of making one server bigger, we add more servers.
This is how companies like Netflix, Amazon, and Google scale their applications.
Stage 4: The Database Becomes the Bottleneck
Many engineers assume scaling backend servers solves performance issues.
Unfortunately, that’s rarely true.
Even after adding multiple application servers, every server still talks to the same database.
Soon the database becomes the bottleneck.
Common symptoms include:
- Slow queries
- High read traffic
- Heavy write traffic
- Lock contention
- Connection pool exhaustion
The first optimization step is usually:
- Query tuning
- Index creation
- Schema improvements
Eventually, another architectural pattern appears:
Read Replicas
A primary database handles writes.
Multiple replica databases handle reads.
Instead of every read hitting one database, traffic gets distributed.
This dramatically improves scalability and read performance.
Stage 5: Redis and Caching
Even read replicas have limits.
Many applications repeatedly fetch the same data:
- User profiles
- Product details
- Trending content
- Configuration settings
Fetching this data from the database every time is wasteful.
This is where caching enters the picture.
Most companies use Redis.
The request flow becomes:
- Check Redis first
- Return data immediately if found
- Query database only on cache miss
This reduces database load significantly.
Because Redis stores data in memory, responses are often returned in milliseconds.
This is one reason Redis has become one of the most widely adopted technologies in modern backend systems.
Stage 6: Asynchronous Processing and Queues
As the application continues growing, another challenge emerges.
Some operations are inherently slow.
Examples include:
- Sending emails
- Processing videos
- Generating reports
- Delivering notifications
If users wait for these operations to complete, API latency becomes unacceptable.
Instead of processing everything synchronously, companies introduce message queues.
Popular options include:
- Kafka
- RabbitMQ
- Amazon SQS
The flow changes dramatically:
- API receives request
- Task is pushed into a queue
- API responds immediately
- Background workers process tasks asynchronously
This architectural shift improves:
- Performance
- Reliability
- Scalability
Once systems reach a certain size, queues become almost unavoidable.
Stage 7: Global Scale and CDNs
Now imagine users are spread across the world.
You have customers in:
- India
- United States
- Europe
- Australia
Another challenge appears.
Latency.
Users located far from your servers experience slower loading times.
This is particularly noticeable for static content:
- Images
- Videos
- CSS files
- JavaScript files
To solve this problem, companies introduce CDNs (Content Delivery Networks).
A CDN stores copies of static files across geographically distributed edge locations.
Instead of serving content from one central server, users receive content from the nearest edge location.
The result:
- Lower latency
- Faster page loads
- Better user experience
Stage 8: The Rise of Microservices
As organizations become larger, architecture evolves again.
The challenge is no longer just traffic.
The challenge becomes organizational complexity.
Multiple teams are now working on the same codebase.
The monolith becomes harder to maintain.
To solve this, companies gradually split the monolith into independent services:
- Authentication Service
- Payment Service
- Order Service
- Notification Service
- Recommendation Service
This is known as Microservices Architecture.
An important lesson often gets overlooked:
Microservices are usually not the starting point.
They appear later.
After traffic growth.
After scaling challenges.
After team growth.
After organizational complexity increases.
Stage 9: Observability Becomes Critical
At massive scale, failures become normal.
Servers crash.
Databases fail.
Caches disappear.
Queues lag.
Networks experience issues.
The question is no longer:
“Will something fail?”
The question becomes:
“What failed and how quickly can we identify it?”
This is where observability enters the picture.
Modern observability consists of:
- Monitoring
- Logging
- Metrics
- Distributed Tracing
Popular tools include:
- Prometheus
- Grafana
- OpenTelemetry
Without observability, debugging distributed systems becomes almost impossible.
As the saying goes:
You cannot fix what you cannot see.
The Real Secret of System Design
Most people think system design is about learning technologies.
It’s not.
System design is fundamentally about identifying bottlenecks and solving the next bottleneck.
That’s it.
The journey usually looks like this:
One Server → Multiple Servers → Load Balancers → Read Replicas → Redis → Queues → CDN → Microservices → Observability
Every component exists because a previous bottleneck became painful enough to justify additional complexity.
Understanding this evolution is far more valuable than memorizing architecture diagrams.
Because once you understand the bottleneck, the solution becomes obvious.
And that’s how real backend systems evolve—from one user to millions.